[Kubernetes] kube-scheduler源码分析(二)
文章目录
上篇介绍了调度的PreFilter,Filter,PreScore,Score部分,本文将介绍Preempt部分。
在调度过程中没有合适的节点能够调度pod则会发生抢占,
|
|
在抢占阶段还将会用调度阶段的节点快照信息,
|
|
在抢占节点会先检查pod是否能进行抢占。其中如果pod.Status.NominatedNodeName不为空,并且提名节点上有正在删除的pod则不会发生抢占,当然还有一些其他条件来判断是否会发生抢占,
|
|
接着会根据调度阶段的返回结果进行初步筛选能进行抢占的Node节点。nodesWherePreemptionMightHelp将会根据调度返回的结果进行过滤节点,如果过滤的节点码不是UnschedulableAndUnresolvable则都有机会进行抢占。
然后会进行抢占调度的节点选择,在selectNodesForPreemption会并行启动多个协程进行节点筛选,
|
|
在上面的函数中可以看到最终的筛选是在匿名函数checkNode的selectVictimsOnNode完成。接下来详细分析这个函数,在这个函数中会先定义两个匿名函数removePod和addPod,抢占可以分为以下几个步骤,
- 找到节点上优先级比抢占的pod低的pod,并执行
removePod,在这里会执行各个plugin定义的RemovePod操作,默认实现这个操作的插件有interpodaffinity,podtopologyspread,serviceaffinity; - 通过
podPassesFiltersOnNode检查pod是否符合在node节点上运行,这个就是调度策略的那个函数,同样会执行两边,检查nominated是否满足,再检查已经调度上的是否满足; - 按照优先级排序需要删除的pod,排序算法为先看pod的优先级,然后看pod的启动时间,启动越早优先级越高;
- 通过
filterPodsWithPDBViolation计算需要删除的pod是否满足pdb的要求,并最终将结果返回在两个pod slice分别是violatingPods和nonViolatingPods; - 根据上面选出来的
violatingPods和nonViolatingPods,通过匿名函数reprievePod尽可能多的将pod重新调度到这个节点上;
|
|
上面分析完内置的抢占逻辑之后将会运行用户通过extender方式扩展的抢占逻辑,这里会用上面过滤出来的结果进行再次过滤,
|
|
最后在上面的结果中选择一个node节点,选择的原则是,
- 节点需要驱逐的违反PDB的pod最少的节点;
- 节点需要驱逐pod的最高优先级最小;
- 如果上面还存在多个node,则分别将这些node上pod的优先级相加,取和最小的节点;
- 如果上面还存在多个节点,则会选择需要驱逐的pod数量最小的节点;
- 终极办法,选择最高优先级中pod创建时间最近的节点。
最后通过getLowerPriorityNominatedPods将抢占pod上低优先级的nominated的pod选出来,
|
|
到这里抢占的主要逻辑基本讲完了,后面将分析选出节点之后的操作。
|
|
最后清理需要清理的nominatedPod,通过k8s client修改pod.Status.NominatedNodeName为空
|
|
到这里抢占逻辑全部分析完了,最终也将整个逻辑大致画了一个图,可以参考一下。
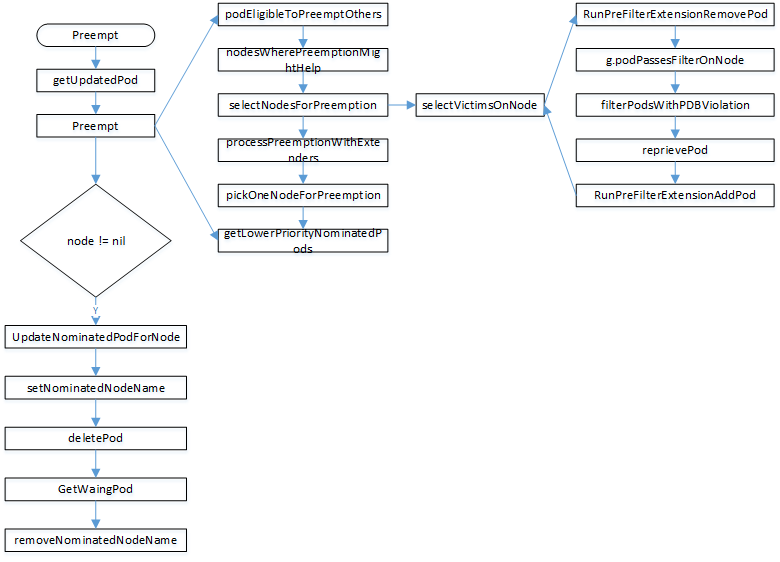
到这里抢占逻辑也分析完了,后面将分析framework架构中的其他部分。
文章作者 zForrest
上次更新 2020-10-05 18:03